C/C++ 编译器 - 编译
编译阶段,根据目标处理器的架构,编译器会将预处理器生成的代码转化为对应的汇编指令。 汇编阶段,汇编器会把汇编指令转化为机器码或者目标文件
编译和汇编
回到我们的项目,恢复项目属性页的设置如下:
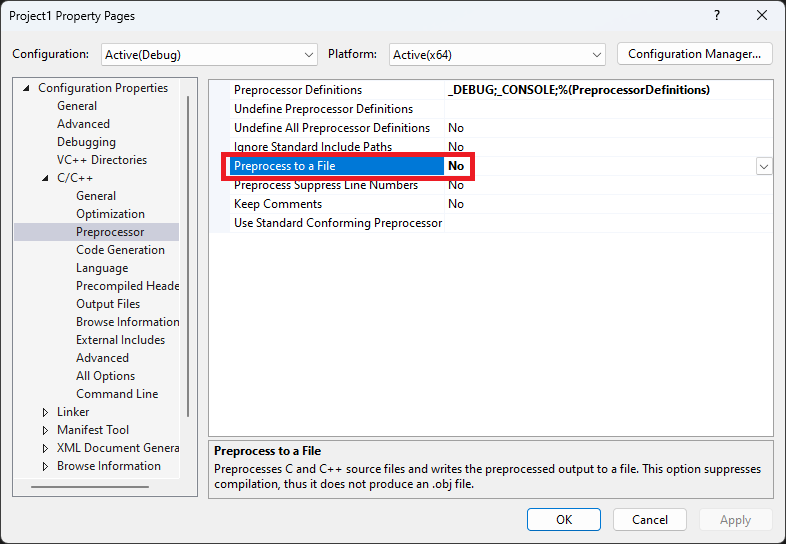
代码也恢复到如下内容:
int add(int x, int y)
{
int result = x + y;
return result;
}
按 Ctrl + F7,编译 math.cpp 文件。你会得到一个 math.obj 文件,用编辑器打开 math.obj 文件,内容大概是下面这个样子:
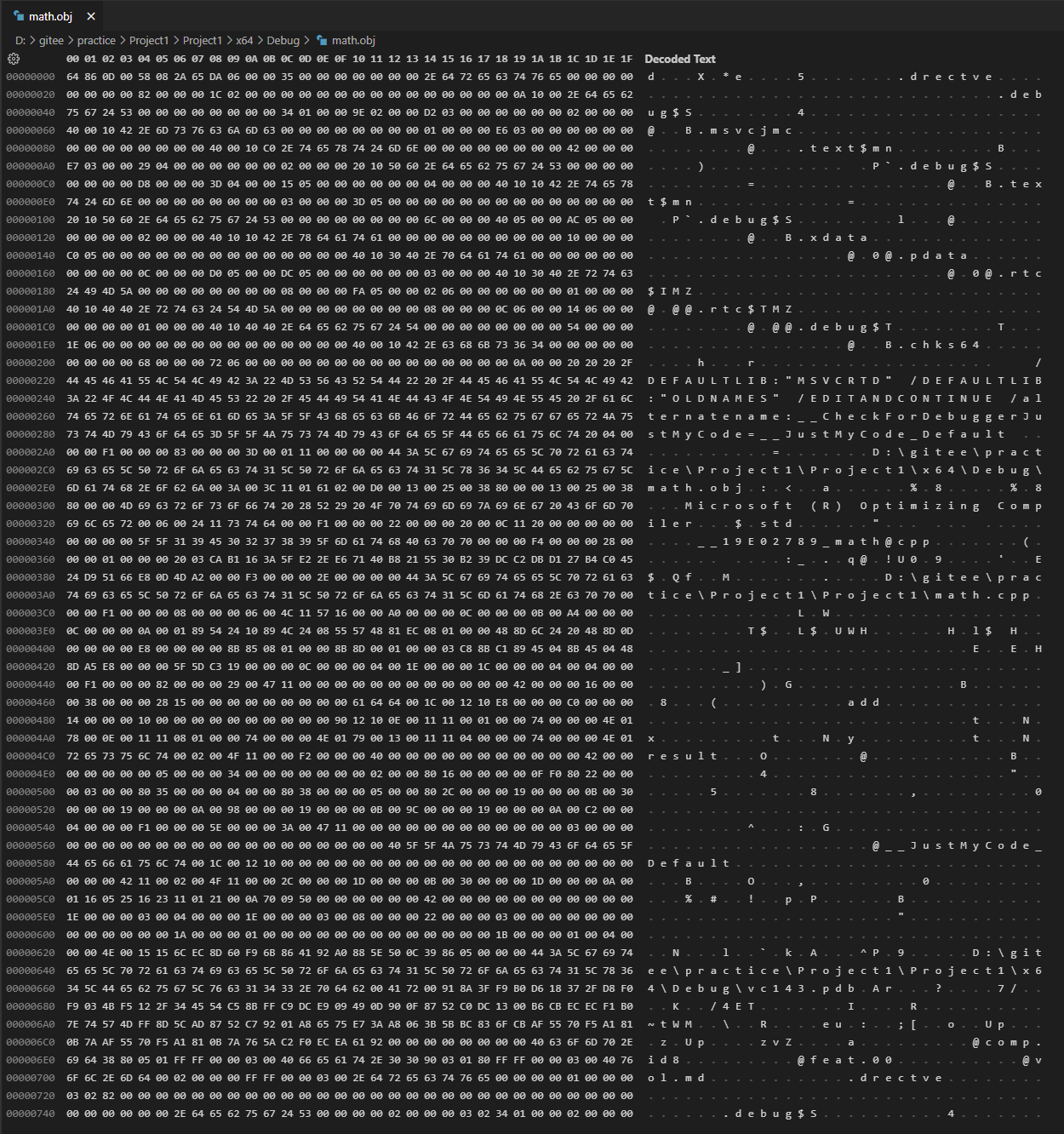
基本没有可读性,但这就是调用 add 函数时,CPU 运行的机器码。让我们把它转换成更容易读懂的方式,将项目属性页设置为如下:
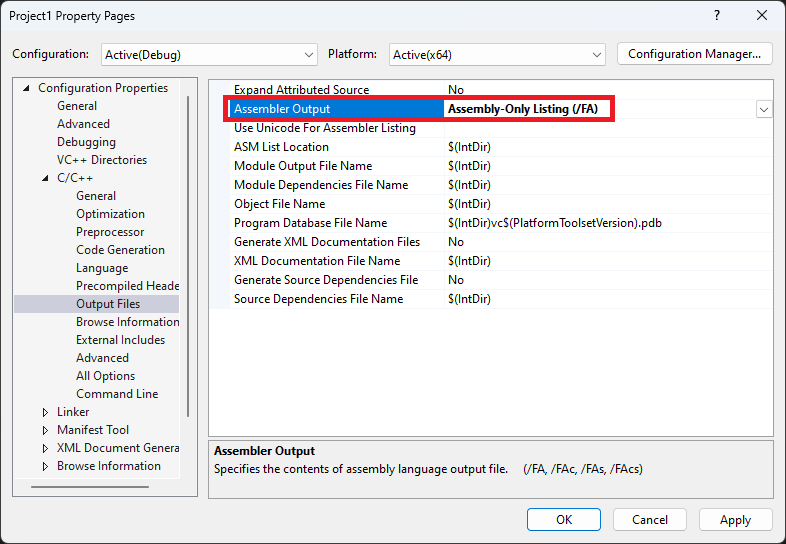
按 Ctrl + F7,在输出目录下,你应该会看到一个 math.asm 文件,用编辑器打开可以看到如下结果:
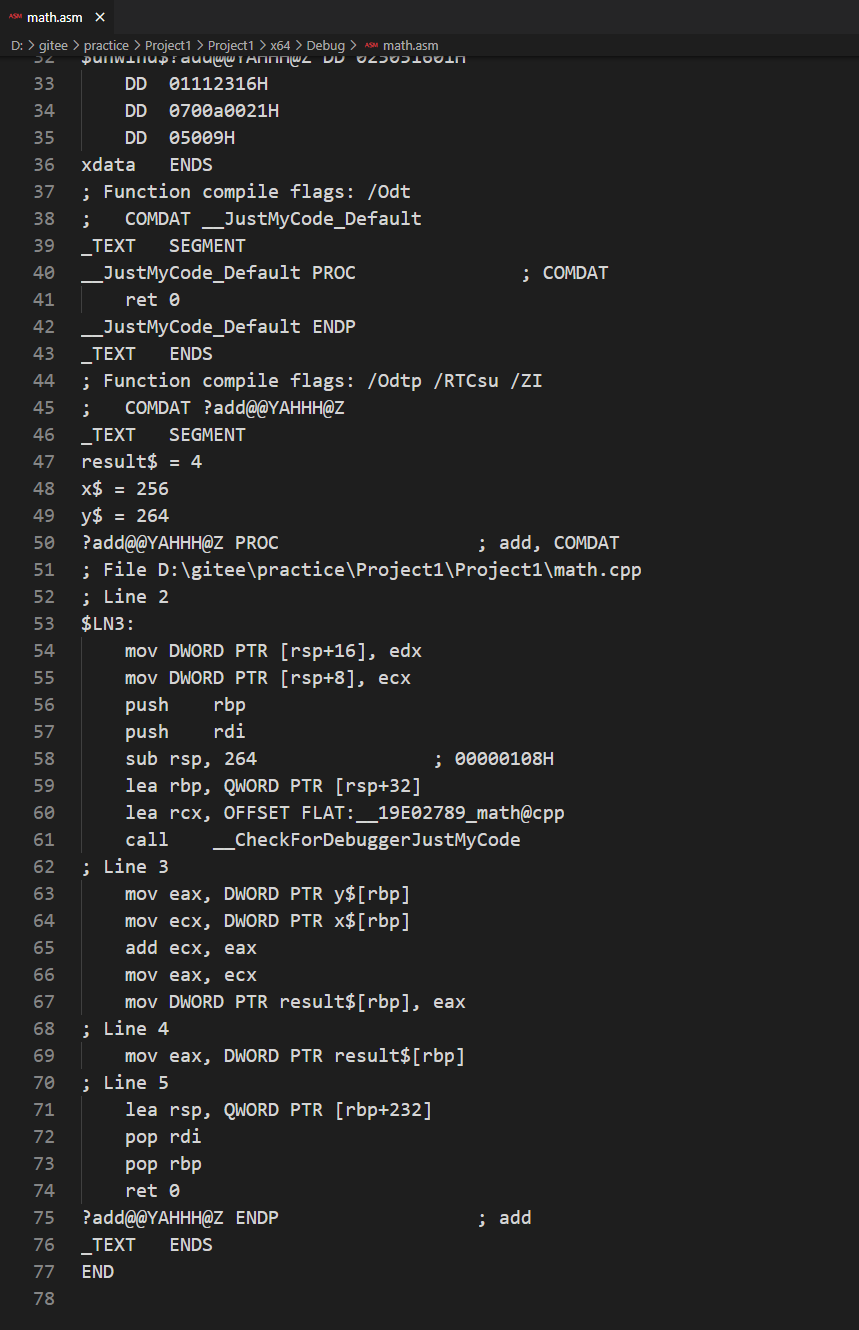
如果你有一点汇编基础,基本可以读懂它。
现在看起来有很多代码,那是因为我们在 Debug 模式编译,它没有做任何优化,还做了很多额外的事情。我们可以通过以下设置让编译器做一些优化:
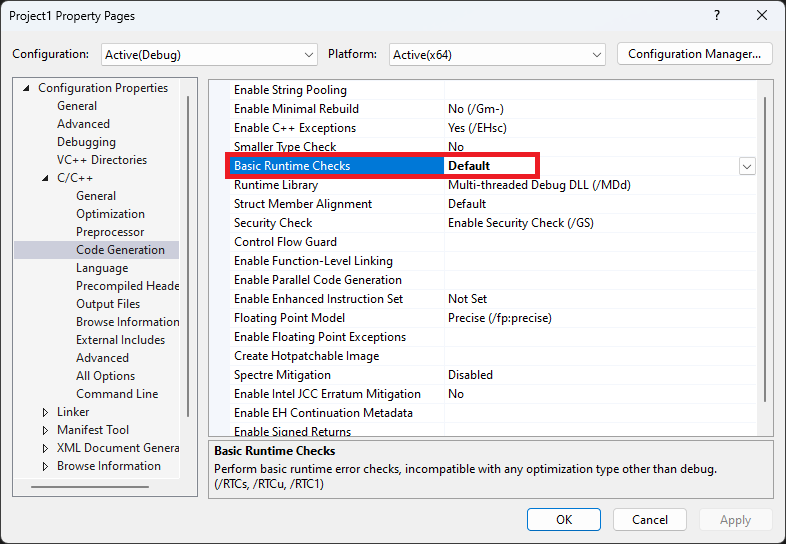
按 Ctrl + F7,然后再用编辑器打开 math.asm 文件,可以看到少了十几行:
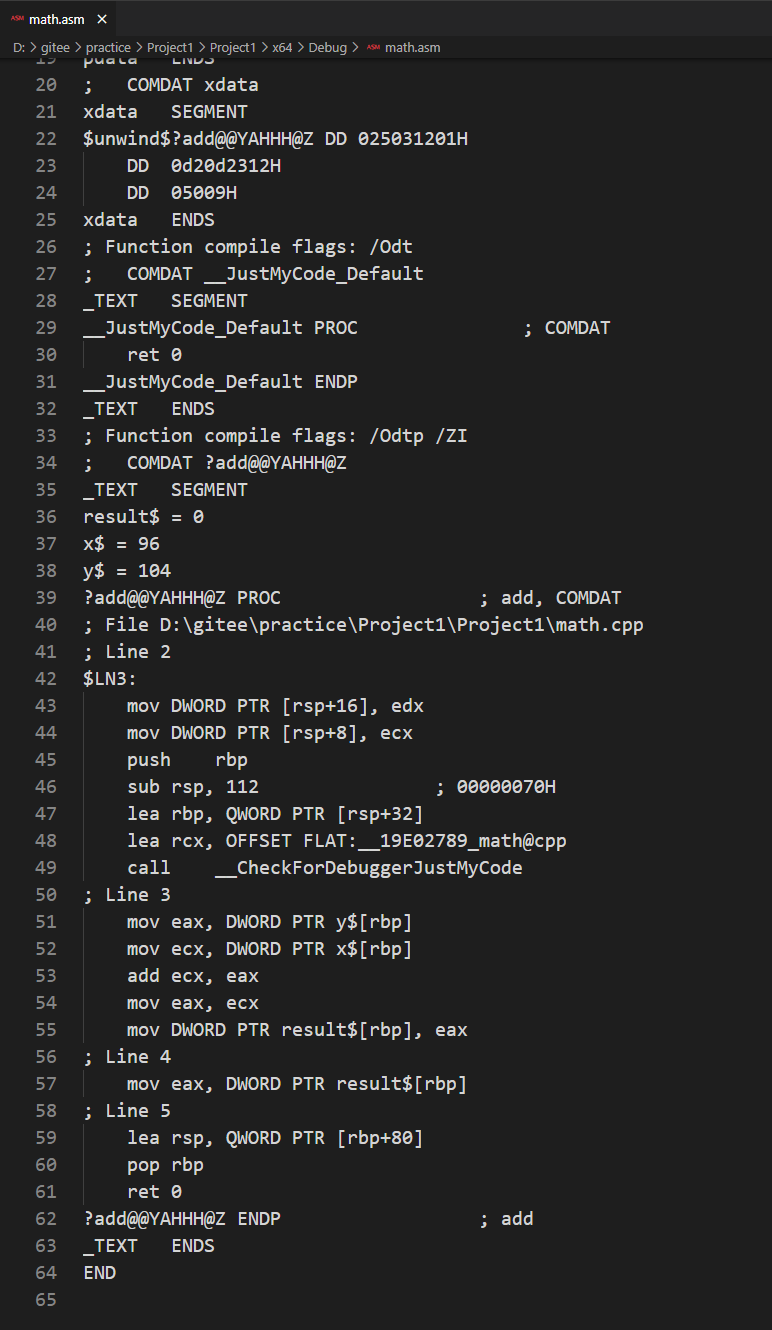
你现在应该有一个基本的概念,当你告诉编译器优化时,编译器实际上会做很多事情。让我们再看一个高级点的东西,将 math.cpp 的内容改为:
int add(int x, int y)
{
return 10 * 10;
}
进入项目属性页,确保 Optimization 为 Disabled(/Od):
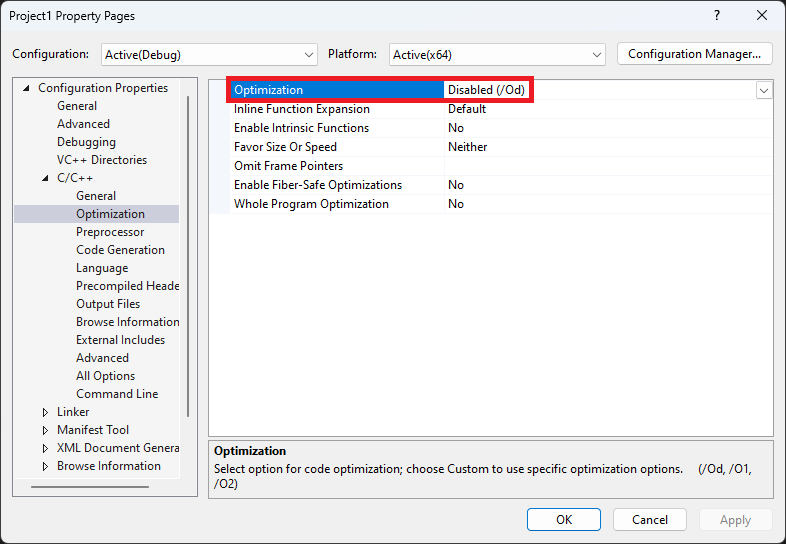
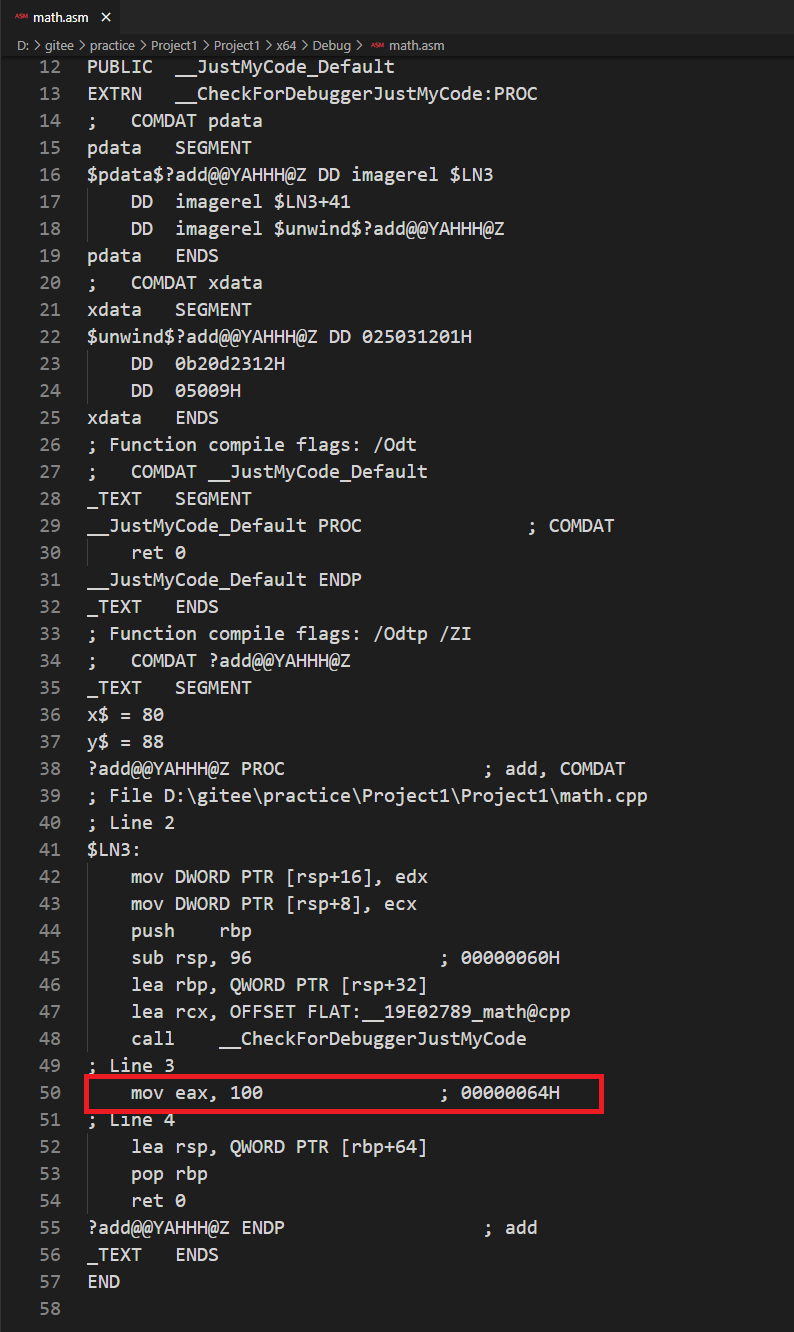
按 Ctrl + F7,查看 math.asm 文件,没有看到像 10 * 10 这样的东西,而是直接得到结果 100。
我们来看一个更有趣的例子,在 math.cpp 中添加一个 log 函数,代码如下:
const char* log(const char* message)
{
return message;
}
int add(int x, int y)
{
log("add");
return x * y;
}
按 Ctrl + F7,看看编译器生成了什么:
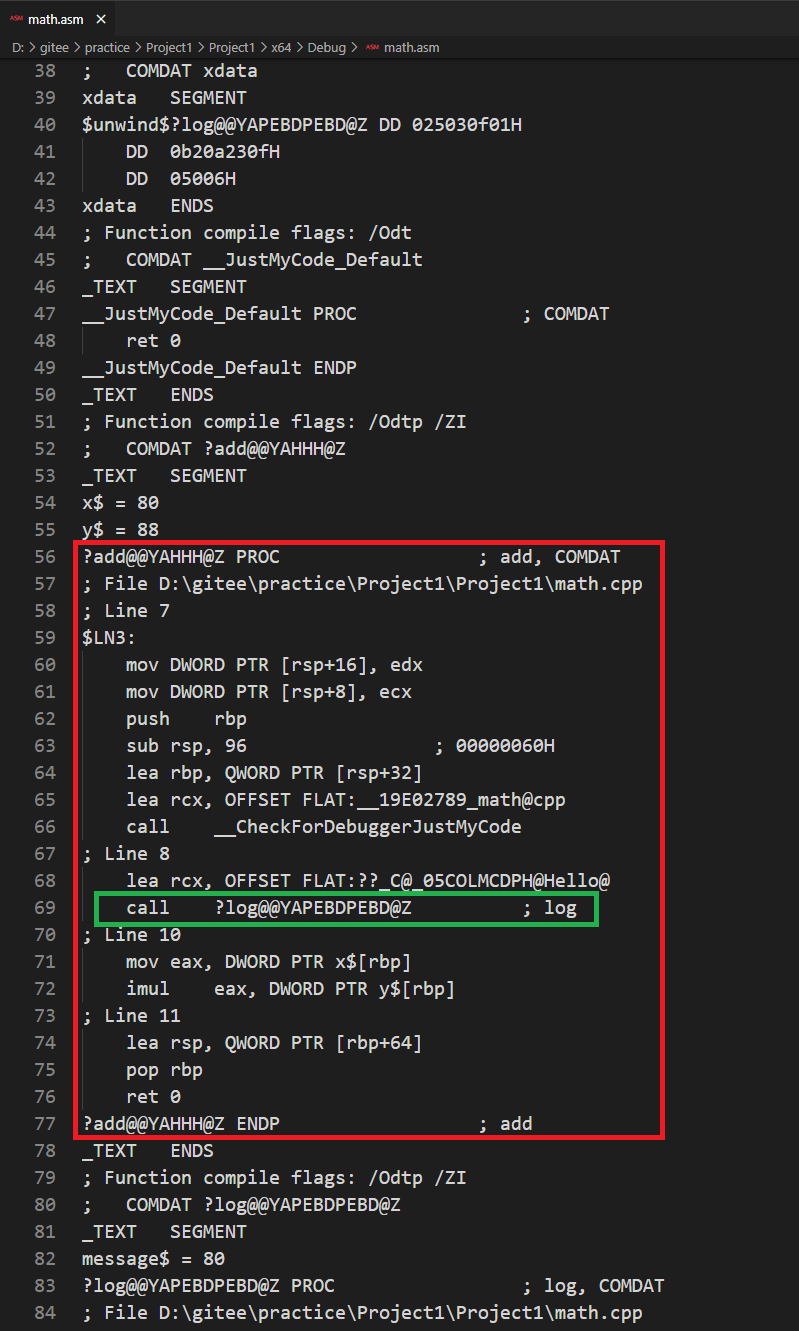
log 函数名像是被一堆随机字符装饰了,这实际上是函数的签名。这需要唯一地定义你的函数,当我们有多个 obj 文件时,函数也被定义在多个 obj 中,链接的工作就是把所有的函数,链接在一起,这样做是为了查找这个函数的签名,所以你在调用函数时,实际做的事情是生成 call 指令。
当然,在这种情况,它可能有一点不是很聪明,因为我们只是调用 log 函数。我们甚至没有要求存储返回值,这些也可以被优化的。
总结
编译器将获取源文件并输出一个 obj 文件,obj 文件是包含机器代码的文件,以及其它我们定义的常数数据。
我们可以将这些 obj 文件链接成一个包含所有内容的可执行文件,可执行文件包含了运行的及其代码,就是我们就可以让 C++ 程序跑起来了。